
Un intérprete es un programa que lee código fuente y se encarga de ejecutarlo. En este artículo vamos a hablar de sus etapas y las principales tareas que realiza, para darte la idea de cómo funciona y si lo deseas, puedas tener idea de cómo hacerlo tu mismo.
Empecemos por hablar de la diferencia con un compilador.
Intérprete vs compilador
Ambos tipos de programas tienen la característica de recibir código fuente, pero la diferencia está en lo que devuelven, y por lo tanto en las etapas que les permiten lograrlo.
Un compilador traduce el código fuente a otro lenguaje, normalmente a un
lenguaje máquina que puede ser ejecutado por un procesador de una arquitectura
específica. Pero esto no es necesariamente así, ya que la principal tarea del
compilador es traducir. Un ejemplo es el compilador de Java:
no compila al lenguaje de una arquitectura de procesador específica, sino a
bytecode que puede ser ejecutado por la JVM. Si no sabes que es el bytecode,
hablamos de él en este artículo.
Los compiladores tradicionales compilan el código fuente a código máquina, es decir, a las instrucciones que un procesador puede ejecutar directamente. Así, si quieres ejecutar un programa de C o de C++ en un procesador con arquitectura x86, necesitas un compilador traduzca para las instrucciones de esta arquitectura. Si después requieres ese mismo programa para ARM, necesitas compilar de nuevo.
Un intérprete también recibe el código fuente, pero en lugar de devolver la traducción en otro lenguaje, ejecuta el código fuente directamente. A veces este proceso tiene como producto secundario la traducción del código fuente en un lenguaje intermedio, pero su objetivo principal es la ejecución.
Ahora sí hablemos de las etapas de un intérprete.
Las etapas de un intérprete
Para ejecutar el código de un programa, podemos dividir el trabajo en varios pasos. Para entenderlo pongamos un ejemplo. Supongamos que alguien te pide que hagas una tarea, por ejemplo, un trabajo escolar. Si tú fueras el intérprete, tendrías que hacer más o menos los siguientes pasos:
- Leer las instrucciones de la tarea.
- Entender claramente y sin ambigüedades lo que se te pide.
- Crear un plan para ejecutar la tarea.
- Ejecutar uno a uno los pasos del plan.
Esos son los pasos que un intérprete hace para ejecutar un programa.
- Tokenización: Leer el código en fuente y transformarlo en una forma que pueda entender.
- Parsing: Convertir el código fuente en una estructura de datos que pueda ser ejecutada. En nuestro plan esto serían los pasos 2 y 3.
- Ejecución: Ejecutar uno a uno los pasos del plan para lograr el resultado.
Parsing o Parseo - Análisis léxico y sintáctico
A veces a la etapa completa de leer el código fuente y convertirlo en una estructura de datos que pueda ser ejecutada se le llama Parsing.
¿Cómo puede un programa informático leer un programa y entenderlo? Lo hace de forma limitada, claro, pero lo suficiente para poder ejecutar el código. Un lenguaje de programación es un lenguaje creado a partir de un alfabeto (un conjunto de símbolos), que a su vez forman palabras y estas palabras forman sentencias. Un programa, por lo tanto, es una secuencia de sentencias.
Para que un intérprete “entienda” un programa, la primera etapa consiste en convertir el código fuente (un conjunto de símbolos), en una secuencia de palabras conocidas por el intérprete. Esto es un tipo de clasificación de las palabras. A la representación interna de estas palabras en el intérprete se le llama tokens. Debido a que en un lenguaje es muy importante el orden de las palabras, esta clasificación debe mantener el orden de las palabras. Como te imaginarás, este proceso es al que se le llama tokenización.
Después de tener la lista de palabras conocidas, necesitamos “entenderlas”. Como un lenguaje tiene una estructura, esta estructura.
Después, este conjunto de tokens es convertido en una estructura de datos llamada el Árbol de Sintaxis Abstracta o AST (Abstract Syntax Tree). Este proceso se llama parsing, que en inglés significa “analizar”.
Construcción del AST
Ya con la lista ordenada de tokens que representan el programa, tenemos que construir la estructura de datos que representa las operaciones que vamos a ejecutar, el AST.
Esta estructura se parece a un árbol, con cada nodo representando una operación
que a su vez puede estar compuesta de más operaciones, es una
estructura recursiva. Por ejemplo, si tenemos un programa muy sencillo como
a = 1 + 2, el AST podría verse así:
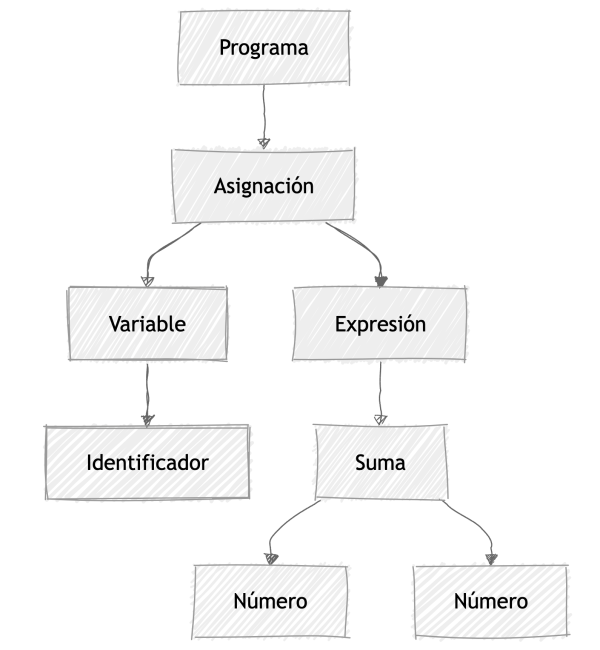
En el esquema anterior puedes ver lo que más o menos es un árbol de sintaxis abstracta: una estructura que nos va ayudar a ejecutar el programa. Para mi, este es el centro tanto de un compilador como de un intérprete, si tienes bien definido este árbol (y por lo tanto todas las operaciones que son posibles de representar en él), tienes hecho la mitad del trabajo, tanto para compilar a otro lenguaje como para ejecutar directamente el trabajo.
Pasemos a la siguiente etapa.
Ejecución
Lo que sigue es lo más sencillo de entender (pero tal vez no de implementar): la ejecución del programa. El intérprete debe tener la capacidad de actuar sobre el sistema operativo para ejecutar las operaciones representadas en el AST. Si el intérprete corre en alguna otra cosa que no sea directamente el sistema operativo, por ejemplo en una máquina virtual, u otro programa, las acciones son diferentes, pero la idea es la misma: debe tener la capacidad de actuar sobre el programa en el que corra.
Opcional: optimización
Varios de los intérpretes modernos tienen que se usan en entornos de producción, tienen una etapa que no es absolutamente necesaria, pero que da una ventaja significativa en el rendimiento y uso común: la optimización del la ejecución.
Estas optimizaciones pueden darse desde mejoras en el AST hasta la generación de código específico para la arquitectura del procesador en el que se ejecute el programa y ejecutarlo inmediatamente. Hablamos de esta última técnica.
Compilación Just In Time (JIT)
Una forma de optimización usada por los intérpretes y máquinas virtuales es lo que se conoce como Just In Time Compilation. La idea es sencilla:
- Se ejecuta el código fuente original mientras se observa el comportamiento de este programa con un perfilador (o profiler).
- Una vez que el perfilador detecta cosas que se pueden optimizar, un compilador especializado en la arquitectura del procesador en el que el intérprete está corriendo genera código máquina específico para es arquitectura de las partes que se pueden optimizar.
- El código máquina optimizado se ejecuta mientras se sigue observando el comportamiento del programa.
- Si el programa no se comporta de la forma esperada, esta parte de la ejecución se cancela y se vuelve a ejecutar el código fuente original.
Tenemos un artículo completo sobre JIT en este enlace.
Conclusión
Ahora entiendes mejor cómo funcionan los intérpretes de manera general. Este conocimiento te puede ayudar cuando trabajes con ellos y probablemente tengas algún problema directamente relacionado con su funcionamiento interno.
También tienes el conocimiento básico para avanzar a aprender cómo hacer el tuyo en caso de que lo necesites. En un artículo futuro hablaré sobre cómo hacer un intérprete de un lenguaje de programación sencillo, para entender todavía mejor el funcionamiento.




Comentar